
GPT-4: It's not "just statistics".
And a simple experiment on a small language model.

GPT-4 is just statistics, just predicting the next token, it has no real understanding.
Right?
Probably not. In parts 1 and 2, I’ll present a mathematical argument to show that if GPT-4 is doing statistics, they are not the sort of statistics that would imply a lack of understanding.
Then in part 3 I will go a step further, and run a transparent and reproducible experiment that demonstrates how a GPT-like transformer model can learn not just surface statistics of a dataset, but rather the underlying process that produced that data, in a way that would be impossible to do through lesser means.
Part 1: What do people mean by “statistics” anyway?
Let’s get these goalposts planted in the ground, because “statistics” has no definite meaning beyond “involving inference from observational data”.1 By that measure anything can be statistics, including almost all of human thought. Since humans are very impressive creatures that do impressive things, and when people say “GPT-4 is just doing statistics” it is mostly meant to sound dismissive rather than impressed, clearly a certain lesser kind of statistics is implied.
So by “just statistics” I mean a heuristic based on correlations between words, standing in contrast with a mechanistic (or algorithmic) model. I think this view was most eloquently expressed by Bender et al in the paper that coined the term “stochastic parrot”:
Contrary to how it may seem when we observe its output, a [language model] is a system for haphazardly stitching together sequences of linguistic forms it has observed in its vast training data, according to probabilistic information about how they combine, but without any reference to meaning: a stochastic parrot.
— On The Dangers of Stochastic Parrots: Can a Language Model Be Too Big? (2021)
If you’re still not sure of the difference, think of a royal court astronomer attempting to predict future eclipses based on just searching for patterns in historical records of past eclipses. If this astronomer emerges from their study having found the 223-month Saros eclipse cycle, it would be fair to label this work as “just statistics”. If the astronomer, in the course of their work, derives Newton’s laws of gravity, it seems fair to label this as “not just statistics”. The astronomer would have found not only the surface-level pattern, but also the compact, underlying laws2 that correctly predict eclipses for never-observed planets in never-observed orbits.

In 1948, Claude Shannon published the groundbreaking thesis A Mathematical Theory of Communication, founding the field of information theory in the same stroke.3 In it, Shannon briefly examined a process for compressing text for the purpose of digital transmission,4 which he called the “series of approximations to English”.5
The text below starts with uniformly-random words comprising the first line. The second line has its words drawn according to their relative frequency of occurrence in English, and on the third line, according to the frequency with which they follow the previous word.6 As n increases, the text gradually starts to resemble more meaningful English.
n = 0: RECEIVE FALL SURPRISED FRIDAY INGREDIENT…
n = 1: REPRESENTING AND SPEEDILY IS AN GOOD…
n = 2: THE CHARACTER OF THIS POINT IS THEREFORE…
These are called n-gram models, where n is the depth of statistical correlation considered by the model (n = 3 would consider triplets of words, and so on). Among language models, n-grams fit the bill for “just statistics”, even as n becomes very large. There is no representation of concepts or abstraction; words are being sampled purely based on their correlations with the previous words. And yet, as further layers of statistical correlation are applied, the results start to become impressively natural.
Many people seem to think of GPT as a fancy n-gram. It’s not! It’s really not!
It’s an easy mistake to make, because the way GPT works is, in a certain sense, functionally equivalent to an n-gram, but that doesn’t mean GPT is an n-gram. If this sounds like a contradiction, let me just illustrate with a chess example.
Part 2: Why GPT must learn abstractions
We could imagine designing a chess-playing program that consists of a huge database of chess positions, and for each position, some recommended next moves. Each turn, the chess program picks a move corresponding to the current table state. As far as chess programs go, if the database is comprehensive and the recommendations are sufficiently good, this program could mimic any other chess program. Let’s call this the “playbook method”.
Now consider Stockfish, a world-leading open-source chess program. There is no way to tell, merely by playing against Stockfish and without inspecting its source code, whether or not it is using the playbook method internally. You could even use Stockfish to generate a chess playbook by repeatedly querying it and recording its output, and if you did this comprehensively, that playbook would essentially be a complete representation of Stockfish’s decisionmaking. If you wanted to emulate Stockfish or reason about its output, the playbook could be a perfectly valid mathematical model.
But that Stockfish playbook does not represent how Stockfish works, and the proof of that is that Stockfish’s source code (including its evaluation network) occupies less than 50 megabytes on my hard drive, whereas its playbook equivalent would be so big that storing it would cause my laptop to immediately collapse into a black hole.7 Since I survived to write this article, Stockfish must be doing something more clever that achieves the same goal of playing chess.
 - https://www.jpl.nasa.gov/news/black-hole-collision-may-have-exploded-with-light")
I’m not sure about GPT-4, but GPT-3's token dictionary contains about 50,000 tokens.8 Its context window — the length of correlations that it can consider, and roughly equivalent to the n of an n-gram — is 8000 tokens long. It is thought to contain 1 trillion parameters, although some sources say it’s as high as 170 trillion. That’s a lot of parameters! It sure sounds like brute-force statistics, doesn’t it?
Yeah, so… how many parameters would we need to build the n-gram model that mimics GPT-4?

THE CAT CHASES THE MOUSE THAT FRIGHTENED THE DOG as the most likely continuation of an initial state THE CAT CHASES. The transition probabilities are represented here by the weight of the connecting arrow. The 2-gram only remembers the previous token. It can encode some ideas, like that a mouse is unlikely to frighten another mouse, but not very compactly.An n-gram is a type of Markov process that defines transition probabilities between states in a state space. The thing is that as you increase the order n of the n-gram, and increase the number of possible states gets big, fast. The volume of GPT-4’s state-space is 50,000⁸⁰⁰⁰ states. For each of those states, we need to define a transition probability to the next token among those 50,000 tokens. That’s about ten-to-the-power-of-38000 parameters. Storing these parameters would not just collapse your laptop into a black hole; it would collapse the entire observable universe into a black hole after barely starting the download.
Does the n-gram model really need all those parameters to mimic GPT-4? Yes, it does. And it gets worse when you consider the size of the dataset needed to calculate those parameters. This is because an n-gram cannot leverage abstractions.
Let’s look at a simple example of applying an abstraction. I have adapted the classic Wolf, Goat, and Cabbage puzzle, which can be found in many books and webpages, but changed the names to something unlikely to have been encountered verbatim.
[Prompt]
Please solve this puzzle.
An Earthling went to the Galactic Federation and met a Martian, a Venutian, and a Moonling. The Earthling wanted to take the wormhole with her back to Earth. But crossing the galaxy by wormhole, the Earthling could carry only herself and a single one of her comrades: the Martian, the Venutian, or the Moonling.
Due to ancient rivalries, if the Martian and the Venutian were left unattended together, the Martian would disintegrate the Venutian with his blaster. If the Venutian and the Moonling were left unattended together, the Venutian would melt the Moonling with her radiation beam.
The Earthling's challenge was to transport herself and her comrades to her home planet, while ensuring they all survived the journey. How did she do it?
In my testing, GPT-4 gets it right.9 The quicker and cheaper GPT-3.5 did not.10 (I’ve put their transcripts in the footnotes; you can click to read their responses).
Solving this should be quite an easy task for anyone who has learned the pattern of this riddle — even if they aren’t good at logic puzzles in general, they should be able to get this just by analogy to the original. All you need to be able to do is regurgitate the memorized Wolf, Goat, and Cabbage solution, while swapping the nouns for any <creature_1>, <creature_2>, and <creature_3>. It is really not a difficult puzzle, but let’s consider what would be necessary for an n-gram model to generate this answer.
Notice the mistakes that the GPTs didn’t make: the solution does not mention a wolf, a goat, a cabbage, or a river. Nor did it even attempt to correct my mis-spelling of Venusian. If you think of GPT as a big n-gram, this should actually surprise you! One can easily gather transition-frequency statistics for sentences like this one:
Jack went to the → {cafe | school | office}But you won’t find the specific sentence below even once in the entire internet,11 let alone often enough to estimate 14-gram transition frequencies:
the Earthling then returns to the Galactic Federation one last time to get the → {Martian | Venutian | Moonling}A 7-gram language model trained on this problem could very reasonably be expected to output “Goat” just by picking up from “one last time to get the”. But for an n-gram to solve this as well as GPT-4 did, it will need transition frequencies that explicitly point to the word Venutian as the correct completion of that specific preceding state, without being able to apply the logical abstraction of “substitute whatever word was used in place of <creature_2> in cases like this”.
A pure n-gram structure is too rigid to allow that sort of indirection, so it needs to be explicitly populated somewhere in that universe-swallowingly-gigantic lookup table. Of course, someone could implement a more sophisticated language model that gets away with a smaller lookup table by tracking unexpected words in its input and identifying analogies with data that exists in its dataset, but would that still be just statistics?
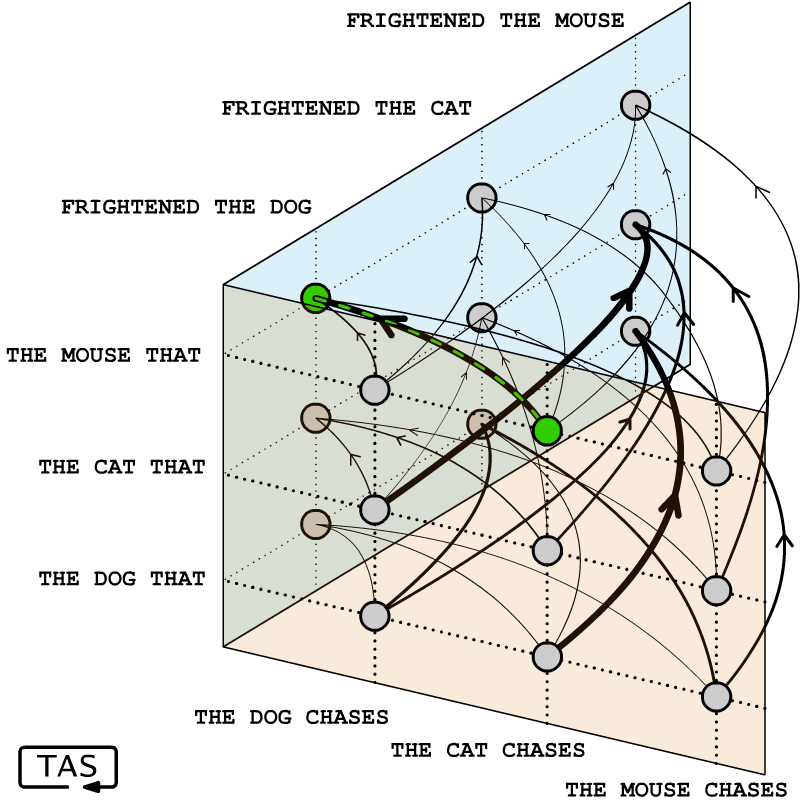
FRIGHTENED THE DOG as the most likely completion of THE CAT CHASES THE MOUSE THAT. Each axis of space represents a choice of token. A 3-gram can encode slightly more complex ideas than a 2-gram, but the cost of doing so grows rapidly. It is hard to do better if there are no regularities or patterns among the transitions, but it gets unwieldy as this gets extended to longer sentences. Learning a more compact “world model” of animal interactions can achieve the same prediction while needing fewer parameters.An abstraction shrinks the required number of parameters by identifying a regularity in the problem space. Instead of needing to independently store transition frequencies for every version of this puzzle over 50,000+ different possible creature names, we can get away with just one pattern. This an example of compression, which is a move in the opposite direction from the process that expands Stockfish into a chess playbook. The more abstract regularities we can find that shrink the problem space, the fewer parameters we need, but as we apply them to our program, it resembles a database less and Stockfish more.
Part 3: Putting transformers to the test
So transformers like GPT-4 aren’t doing token prediction by naïve application of raw statistics. They compress the problem space way too effectively. But will transformers ever develop Newton-like understanding, or just dig up shallow patterns like the Saros cycle?
I don’t expect GPT-4 to fill Isaac Newton’s shoes anytime soon. But let me propose a simple experiment that, I believe, captures the main essence of this question.
If we teach a transformer network to sort lists of random integers, will it just learn the statistics of sorted lists, or will it learn to implement a sorting algorithm?
You might be wondering why we should waste our time training an AI to sort lists when we already have algorithms that can do that perfectly well. Here’s why this is a worthy investigation: First, it should be easy to tell the difference between the output of a sorting algorithm and statistics.12 Second, this is a simple enough problem that the role of each neuron in the trained network might be transparently understandable, rather than training something too vast to understand at a low level. Third, we can compare the learned result against closed-form solutions, which is always a good thing for software validation. And as Bender et al point out, while ChatGPT’s replies can seem sensible and coherent “in the eye of the beholder”, it is plausible that our human psychology is tempting us into reading more depth into those replies than is actually there. The correctness of a sorted list is objectively verifiable.
Also this experiment doesn’t cost a fortune to try, and unlimited training data can be generated on-the-fly without infringing anyone’s privacy or copyrights. So there’s that.
In a nutshell, here’s why sorting is a good test to rule out stochastic parroting:
The correctness of a sorted list is not in the eye of the beholder;
We can easily generate unique lists, both for training and for testing, to verify with confidence that the answer is not merely being copied from some remote corner of a vast and proprietary ocean of training data;
The correctness of each output always depends on the entire input sequence, not just neighbouring tokens; there is no way to succeed without learning some form of counting and ordering along the way.
Sorting, here, is really a stand-in for the general idea of whether the network can learn the underlying algorithm13 that generated the training data it observes — the Newton’s laws of this dataset.
SORT (51,87,46,2,17,46,80,55,3,24,70,73,52,52,11,74,40):
---> [2,3,11,17,24,40,46,46,51,52,52,55,70,73,74,80,87];If you expect it’s possible to sort lists by statistics alone, think just for a minute about what that would look like. Sure, it should be easy to grasp that every second or third character is a comma, and the numbers monotonically increase, and that long lists will often tend to start with [0, or [1, and end with 98]; or 99];. But how many 0s? How many 1s? When is it preferable to start with 2 and end with 87? How often should there be two 46s and two 52s near the middle? There are no statistical shortcuts; every single token in the input counts. If you’re going to sort by pattern-guessing and not by a process that involves actual sorting, it becomes astronomically unlikely that you’ll pull the exact right sequence out of that universe-sized hat. An n-gram can pull this off by mapping every input list to a corresponding output list, but as usual, not without turning my laptop into a black hole in the process.
My expectation for this experiment is that at some point in training, we’ll see the error drop off a cliff, and at that point the neural network will have configured itself to encode a crude sorting algorithm.14 It might not go straight to zero; the learning process involves stumbling around in the dark without even knowing a priori that there’s a deterministic process that generates the data,15 and perhaps it will initially have stumbled on an algorithm for sorting small sub-sequences, mixed in with some guessing. But eventually it should be sorting long lists without error, most of the time.
On the other hand, if it only learns shallow statistics, then there will be many mistakes in the output: it might contain sequences of monotonically-rising numbers, but not every number in the input will be found in the output; repeated occurrences of certain numbers in the input might be dropped, and numbers that were never in the input might be hallucinated into the output. In that case, it will only be able to sort very short lists without error, like 6 or 7 numbers at the most, and only with some luck. Let’s see what happens!
To run this experiment I cloned Andrej Karpathy’s nanoGPT project, and replaced the Shakespeare dataset with lists of random numbers between 0 and 99, up to 127 characters long.16 The context window is twice as long at 256 characters, because the first entry needs to still be in context by the time it’s gotten to the end of the list. Each character 0-9, as well as the comma separators and the parentheses are their own token.
It’s trained the normal way language models are, just predicting the next token. But to judge its performance at sorting throughout the training process, I periodically sample its output across ten random input lists of various lengths.17 Rather than attempt to judge “how good” a sort is, I score all-or-nothing: only a perfectly sorted list, with no missing or excess numbers or misplaced commas, and terminated with ‘];’ is admissible. In that sense, even scoring one point would be fairly impressive.
Here are the results after one day:

I would call this a success. I don’t expect this network will sort every given list flawlessly (yet), but it’s already performing far too well to be regurgitating memorized patterns. One thing does jump out though: what went wrong after 166,000 steps? It suddenly goes from getting everything right, to everything wrong. I looked at the log, and found that the same mistake was being made with every single list: each output was sorted correctly, with the exception of dropping a single number. For example:
INPUT (43 numbers): (59,44,48,74,43,0,85,55,36,16,84,40,35,41,70,20,43,21,24,7,18,11,75,70,63,93,47,1,44,1,65,20,87,21,94,79,29,7,18,95,66,11,91):
EXPECTED: [0,1,1,7,7,11,11,16,18,18,20,20,21,21,24,29,35,36,40,41,43,43,44,44,47,48,55,59,63,65,66,70,70,74,75,79,84,85,87,91,93,94,95];
OUTPUT: [0,1,1,7,7,11,11,16,18,18,20,20,21,21,24,29,35,36,40,41,43,43,44,44,47,48,55,63,65,66,70,70,74,75,79,84,85,87,91,93,94,95]; << did you spot the error?All ten lists from that checkpoint have that exact same error. It seems the training process quickly corrected that mistake and the network returned to (mostly) perfect performance. Curious.
Anyway, I’m satisfied that this little network, trained on my laptop plugged into a single, anemic GPU, cannot possibly be a mere “stochastic parrot”. The math doesn’t work out. It’s sorting numbers by learning an algorithm that sorts them, and as far as I’m concerned, that means it’s doing more than just statistics.
Probably GPT-4 is as well.18
This post isn’t intended as professional engineering advice. If you are looking for professional engineering advice, please contact me with your requirements.
Statistics does have one unambiguous meaning, but I don’t think anyone who says “ChatGPT is just statistics” means “ChatGPT is just the mathematical discipline of Statistics”.
By the way, statisticians: I’m not writing this article to downplay the power of statistics! Only to downplay the power of whatever statistics people must be imagining when they say “it’s just doing statistics” as though that were a bad thing.
Or at least a good approximation to the real laws of planetary motion. I don’t think the “just statistics” crowd would apply that label to everything that fell short of General Relativity.
Shannon’s work is quite central to the themes of These Are Systems, so I expect to come back to it again and again in future articles. You can read A Mathematical Theory of Communication here for free; it is very approachable with just undergraduate mathematics.
Compression and prediction are essentially equivalent processes, because you can use your predictor to compress (or decompress) a stream of data. This is called a predictive encoder, illustrated below, after Fig. 4.5 in Richard Feynman’s Lectures on Computation. Instead of transmitting the original data, you transmit just the prediction errors; if the predictor can do better than 50-50, then the output will include long strings of '0’s where the predictor guessed right.
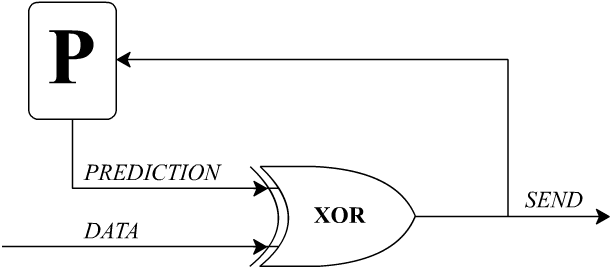
GPT-like programs would be excellent for compressing and transmitting text, or any similar data stream, if they weren’t so resource-intensive to run.
By the way, GPT may be trained as a token predictor, but in a deployed application like ChatGPT, its ‘predictions’ are not being compared against anything. Absent such a comparison, it may be more accurate to refer to GPT as a token selector. I would guess that this terminology hasn’t caught on because “it’s just selecting the next word” doesn’t sound as reductive and mechanical as “it’s just predicting the next word”.
Shannon starts with character n-grams, which I’ve skipped for brevity. He does not provide a 0-gram for words, so I generated a random sentence sampled from the Oxford 5000.
I say “frequency” instead of “likelihood” because the frequency of one word following another is easily and directly measurable given a large sample of text, but the likelihood of one character following another is highly subjective and depends on how sophisticated your information about the message is.
The number of legal chess board positions is about 5×10⁴⁴. Storing even one recommended move per position would take about 2^154 bits, which greatly exceeds the Berkenstein Bound for the volume of my laptop. (Yes, I know, my notation is not consistent, that’s because Substack needs to improve their superscript formatting.)
A token can be a character, word, or word fragment. These are the building blocks that transformer models operate on, distilled from frequently-occurring patterns in the training data, and they essentially form the model’s basic vocabulary. It would be possible to build a model where the tokens were just single characters like [a b c d e f g h i j k l m n o p q r s t u v w x y z , . ? !], but it has so far been found to be more efficient to collect common character-sequences like cat, walk, and egory, which can themselves be assembled into sequences like catwalk and category. For the sake of making this article approachable to a wider audience, who have heard of words but not tokens, I am using “word” as a synonym for “token” when doing so would not confuse the meaning.
[GPT-4’s response]
Here's a solution:
The Earthling first takes the Venutian across the wormhole to Earth. The Martian and Moonling are safe together. She leaves the Venutian on Earth.
The Earthling then returns to the Galactic Federation, leaving the Venutian on Earth.
The Earthling then takes the Martian across the wormhole to Earth. Now the Venutian and the Martian are on Earth, which would be a problem, but the Earthling is there to prevent any violence.
Leaving the Martian on Earth, the Earthling takes the Venutian back to the Galactic Federation.
The Earthling leaves the Venutian at the Galactic Federation and takes the Moonling across the wormhole to Earth. Now the Martian and Moonling are on Earth, and they get along fine.
The Earthling then returns to the Galactic Federation one last time to get the Venutian.
Finally, the Earthling takes the Venutian across the wormhole to Earth.
Now, the Earthling, the Martian, the Venutian, and the Moonling are all safely on Earth.
[GPT-3.5’s response]
To solve the puzzle and ensure the survival of all the beings, the Earthling needs to transport them one at a time, making sure that the Martian and the Venutian are never left alone, and the Venutian and the Moonling are also never left alone. Here's how she can achieve this:
The Earthling takes the Venutian to Earth first and leaves her there.
This ensures that the Martian and the Venutian are not left unattended together, avoiding the disintegration of the Venutian.
The Earthling returns to the Galactic Federation alone and picks up the Martian.
Now the Martian is the only one with the Earthling, and the Venutian is safe on Earth.
The Earthling drops off the Martian on Earth and takes the Moonling with her back to the Galactic Federation.
The Martian and the Moonling are now the only ones together, and the Venutian is safe on Earth.
Finally, the Earthling returns to Earth and leaves the Moonling with the Venutian.
Now the Venutian and the Moonling are together, but the Martian is safely on Earth.
By transporting them one at a time and making sure the incompatible beings are never left unattended together, the Earthling successfully ensures the survival of all her comrades during the journey back to Earth.
Proof:

Except that, yes, it’s on the internet now, in this article. So you’ll need to keep coming up with your own variation if you want to try this test yourself. This is actually something an annoyance for benchmarks, but one that is familiar to schoolteachers and professors coming up with exam problems.
Basically because there are way too many possible random number lists for any technique to work by memorization of statistical patterns instead of algorithmic sorting. Even a few error-free sorts of long lists would be convincing evidence. See footnote 16 for a discussion about the entropy.
Even if this experiment works, and it learns a sorting algorithm, I’m not saying that it will be an efficient sorting algorithm. The training process only scores correctness, not speed. That’s fine.
By the way, transformer networks, in just forward-pass operation as they are used in programs like GPT, are not Turing-complete. Their only working memory is the output, and they can only encode a finite number of sequential operations. The transformer is equivalent to a sort of restricted sequence-to-sequence programming language that Dr. Gail Weiss calls RASP in her fantastic paper Thinking Like Transformers (paper, video). That should still be good enough for sorting, and indeed Weiss proves that it is, and provides an example of a sorting algorithm in RASP. So it’s clear that a sorting algorithm exists somewhere among the possible configurations that a transformer network can assume. However, that doesn’t prove that a randomly-initialized network will be able to learn a sorting algorithm by example, which is arguably the most impressive part.
Here I am counting only the network’s errors on predicting the sorted version of some random input list, then outputting the stop token. The way these things work, it will then go on trying to guess the next randomized input list, and I certainly don’t expect it to be able to do that correctly, so I won’t count any of those errors in its score. (If it could guess its next input, it would actually be quite concerning, because that means it will have reverse-engineered my random number generator somehow)!
What I mean by this is that the transformer’s training process is not only searching among the space of short, deterministic programs that don’t contain infinite loops. It’s also searching the space of stochastic (nondeterministic) programs, which is reasonable because most datasets will include noise. Imagine having many different hypotheses about what could have generated the data, where the default is “it’s all random noise”. Early on in training, it will tend to learn basic patterns like “regardless of the input, flip a coin and based on the outcome, start the output with either [0, or [1,” which are low-hanging fruit that will improve the score compared with total random guessing. But after it finds a true sorting algorithm, it will also need to un-learn any temptation to add those guesses in.
(In fact, even this sorting dataset does contain noise, as I mentioned in footnote 14, because the transformer is also being trained to predict the next input, which is mostly futile. I haven’t given a custom loss function to the training algorithm, so every time the training process updates on successful predictions of the next [random] input, it’s probably learning the wrong lesson, and just tripping itself up. But to avoid confusion about whether this experiment is relevant to GPT-4, I don’t want to move too far away from how large language models are trained.)
127 characters leaves 125 for the list contents, because 2 characters are used for the open and close brackets respectively. Comma separators take up characters too, and two-digit numbers take two characters each. That means it can hold up to 62 single-digit numbers, or 41 double-digit numbers, or some mix. Lists can be random length, including possibly being empty.
It’s rather tedious to calculate the exact number of possible random input lists that can fit into these 127 characters, but I estimate it’s something in the realm of 10^80. To give a sense of scale, that’s on par with the volume of the observable universe in cubic metres. Of course, sorting is a many-to-one operation; there are fewer sorted output lists than shuffled input ones. Calculating the number of possible sorted outputs is (nearly) equivalent to the stars and bars combinatorics problem, the fact that the lists are variable is equivalent to adding one extra bar; this means the number of possibilities is somewhere north of 10^36. Still pretty big: in cubic metres, that’s approximately the volume of the sphere whose circumference is the orbit of Jupiter.
In fact, both of these numbers are underestimates; the transformer’s space of possible outputs includes invalid non-lists like [,,,017()0(77,];, which the network will need to learn not to produce, but we’ll be generous and set that aside.
How big would the n-gram Markov sorter need to be? Let’s take randomness out and make all state-transition probabilities either 0 or 1, so that each state only needs to store a single pointer to the corresponding next state. That should shrink things a bit. If we have n inputs mapping to k outputs, then we need to store n pointers which are each log₂(k) bits. So we need nlog₂(k) bits. log₂(10^36) ≅ 86.4, so we’ll be OK with just 87 bits per pointer; however we still need to store one pointer per input, so 10^80 of those pointers. That’s a black hole. If you could somehow compress, for free, all the redundant inputs that map to the same output list, like [4,3,3] and [3,4,3] which both map to [3,3,4], then you’d only need to store 10^36 87-bit pointers, which takes 10^40 bits. That’s just small enough to not collapse into a black hole, but still way too big for my laptop to possibly manage.
Meanwhile, my NVIDIA RTX 2070 eGPU is quite underpowered for this sort of task, and struggles to train a network with more than 50 million parameters. (Those weights take up about 600 MB on disk, so about 10^10 bits). Even with just 125 characters and numbers 0-99, the space of possible random lists should provide more than enough entropy to avoid concerns about the network simply memorizing all of the answers.
This technique should be able to extend to larger multi-digit numbers if the network can properly learn to generalize how digits work, but that wasn’t the focus of my experiment. I’m sure there are a lot of optimizations that could make the job easier; perhaps it would be more efficient to represent every distinct number by its own unique token like ‘53,’ allowing the network to skip having to learn the concepts of digits and commas, at the cost of a bigger vocabulary. Or perhaps the optimum likes in the other direction, where lists are composed of binary numbers (or even unary numbers!) where multiple digits are heavily used and a longer context window is needed, but allowing a smaller vocabulary of tokens.
I could probably also optimize this all by using RASP to find the minimum size transformer network that can implement sorting and configure my network accordingly with an appropriate number of layers and attention heads, but in practice I just ran with my first guess to see how well it would do. The model weights are available here if you want to play with them.
Short lists aren’t interesting because they’re too easily memorized, but it’s still important to see if the network learns that lists can be various lengths and get them correctly. The ten tested list lengths are 12, 17, 23, 29, 34, 40, and the rest are the maximum length (~43, depending on whether there are more 1- or 2-digit numbers). I tested more large lists than short lists because there are more possible long lists than short lists. The lists are randomly generated each time, and (probably) don’t exist in the training dataset.
If I were to try this experiment again, I’d increase the metric to maybe a hundred lists or more, rather than ten, because that performance plot is pretty coarse. When the network is outputting 10/10 perfect sorts, it’s hard to tell if it would get 100/100. But doing these evaluations adds quite a bit of time; around a third of the training time is spent on them. Since I wasn’t totally sure this experiment would succeed when I started it, I didn’t want to waste too much time gathering high-resolution data, and storing every set of parameters would fill up my hard drive too fast. I was most interested in seeing whether it would work at all, rather than the exact progress of learning. I’ll run it again spending more time gathering training metrics, and post an update with higher-resolution data.
It’s a strange era that we live in that I need to mention this, but other than the riddle answers in footnotes 9 and 10, I did not use ChatGPT or any other large language model to write any part of this article, and I don’t plan to do so for future articles. I like writing.
Chatbots are random processes, so it's important to run each prompt at least a few times to see how consistent it is. (Ideally we'd use the API and do many trials.) I re-ran the river crossing prompt a couple more times on GPT-4 and reproduced your results, but worded differently each time. Interestingly, on the last attempt it explicitly said it recognized the problem:
---
This is a variant of the classic River Crossing puzzle, where you need to transport everyone across without certain groups being left together. Here's a possible solution to the problem:
First, the Earthling takes the Venutian to Earth via the wormhole, then the Earthling returns alone to the Galactic Federation. This leaves the Martian and the Moonling at the Galactic Federation, who are safe together, and the Venutian alone on Earth.
Next, the Earthling takes the Martian to Earth, leaving the Moonling alone at the Galactic Federation. But, she can't leave the Martian with the Venutian on Earth, so she leaves the Martian on Earth and takes the Venutian back to the Galactic Federation.
Then, she leaves the Venutian at the Galactic Federation and takes the Moonling to Earth. This leaves the Venutian and Martian at the Galactic Federation, who are safe together.
Finally, the Earthling returns to the Galactic Federation one last time to bring the Venutian to Earth.
Now, all of them, the Earthling, the Martian, the Venutian, and the Moonling are on Earth, and at no point were the Venutian and the Martian left alone together, nor the Venutian and the Moonling. The Earthling has successfully navigated the wormhole puzzle!
---
If someone wanted to explore this further, they could try varying the prompt to see when it breaks down. If we tell it that the the wolf is a vegetarian and the goat attacks wolves, does it get confused? What if it's given an unsolvable problem?
This is a little different because it's about in-context learning, but I recently saw an interesting paper about how if you give an LLM a problem with backwards labels, it will get confused. See: https://thegradient.pub/in-context-learning-in-context/
---
Edit: In general, I think this is a good post but the headline is overstated. It seems like the boundary between reasoning and statistics gets rather fuzzy once you allow for copying with substitutions, and LLM's are all about copying with substitutions. They're usually not copying word-for-word, but it's often unclear what level of abstraction they're working at.
No it's not able to sort, it's merely applying statistics to the input.
Even Yann LeCun states that GPT-4 is a statistical correlations engine.
In simple terms, it sees multiple times a sequence of characters (say "42" for example) that it puts it in the output, and the output is ordered (sorted) because the neurons are reinforced to output "42" after "41", and "41" after "40" and so on and so forth, and keep the same amount. That's all it does!
The reason why it failed on 59 is because it has seen that number too few times at the first position is all.
*It's only a large statistical model*
You can easily determine if it had internally developed an algorithm to sort number by not giving one number in the input samples (e.g. 37) and train it, then give it 37 in some input and see whether it can sort it out or not.
I already know the answer: the model doesn't have a sense of ordering numbers expressed in base 10 (decimal), it just has a sense of patterns: it matches groups of digits and produce the output that will result in the lowest error rate. Again, that's only statistics.